上海交大与上海人工智能实验室联合团队荣获国际对话系统技术挑战赛知识增强的任务型对话赛道冠军
近日,第十一届国际对话系统技术挑战赛(Dialog System Technology Challenge,DSTC 11)的主题研讨会在捷克布拉格召开,未来媒体网络协同创新中心与上海人工智能实验室联合团队凭借基于多预训练语言模型的协同学习优化算法夺得知识增强的任务型对话赛道冠军,这也是该赛道自建立以来首次由高校和科研单位获得冠军。
作为全球对话技术领域的权威比赛,DSTC由微软、卡内基梅隆大学的科学家于2013年发起,主要聚焦复杂对话理解等领域的挑战,在对话领域具有极高的权威性和知名度,今年吸引了来自科大讯飞、香港中文大学、新加坡国立大学、首尔大学等全球顶尖高校和研发机构的80余支参赛队伍。

参会代表在DSTC Workshop现场介绍参赛系统技术细节
赛道简介
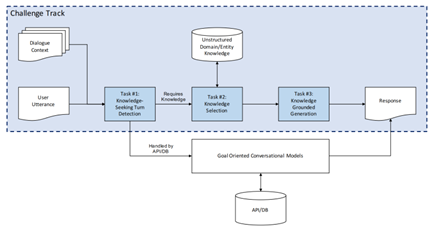
知识强化的任务型对话框架图示
随着人工智能的持续进步,大规模预训练模型在对话系统中得到广泛应用。如何更准确地根据实际应用场景对模型进行知识注入与优化,成为了研究者们关注的焦点。今年DSTC11知识增强的任务型对话赛道着重于如何利用多维人类主观知识对于预训练模型的对话能力进行知识增强,其中涵盖三个核心子任务:
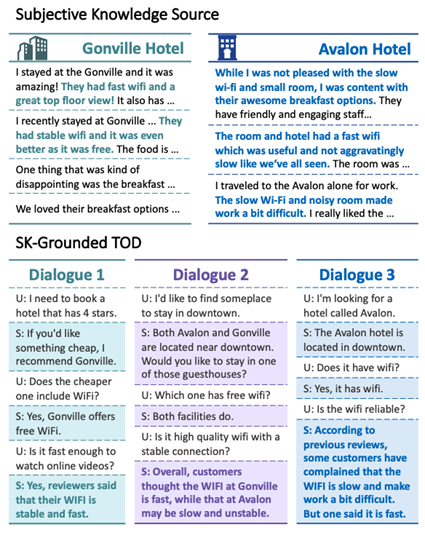
主观知识示例
子任务一:知识检测(Knowledge Detection)。检测用户的询问是否需要主观知识增强来生成回复。
子任务二:知识选择(Knowledge Selection)。根据用户的询问在给定的知识库中检索多条相关的知识。
子任务三:回复生成(Response Generation)。根据检索到的相关知识对用户的询问生成回复。
与先前的任务不同,此任务的挑战在于如何准确地提取与用户询问紧密相关的多条主观知识。由于主观知识本身的模糊性与高度相似性,使得模型在实时检索中容易选择到似是而非的知识,进而对用户提供的回复偏离其实际需求。
技术方案
基于大规模预训练模型的协同学习优化算法图示
为了克服该任务中的关键难题,电院未来媒体网络协同创新中心媒体智能团队的王钰副教授带领其研究小组提出了基于大规模预训练模型的协同学习优化算法,充分利用多个模型在知识建模上的差异性与多样性,通过多阶段自适应策略进行模型决策融合,显著减小模型的不确定性,从而有效提高模型在多个子任务上的性能。该协同学习优化算法为解决关键任务难题带来了突破性的进步,不仅提高了模型的精确度和稳定性,更为复杂的任务建模提供了一种高效且创新的策略。
比赛结果
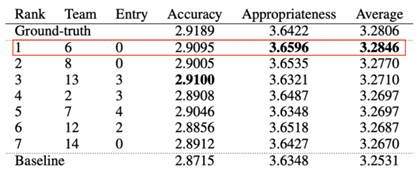
比赛结果
该赛道共有14支队伍共计49个系统参与。未来媒体网络协同创新中心与上海人工智能实验室联合团队在最终的人工测评结果中获得冠军(队伍编号6),不仅击败了来自新加坡A*STAR、LG人工智能实验室、首尔大学等国内外知名机构的队伍,甚至在部分得分上超过了官方的参考标注(Ground-truth)结果,证明团队在对话系统技术领域所提出的最新技术方案不仅在理论上有所突破,而且在实际应用中同样卓有成效。